Reduce Noise on Your PostgreSQL Read-Replicas
Table of Contents
Use mechanisms like streaming delay and synchronous commit to make your read-replicas perform better
There are already various articles that demonstrate how to setup a hot standby replica in detail. The aim of this article is to walk through some performance degradation scenarios and discuss potential improvements with their tradeoffs.
First, let’s talk about the key components in play here.
PostgreSQL Caching and Persistence #
The buffer cache (aka shared buffers) is a fundamental component of modern RDBMSs, and PostgreSQL is no exception. This in-memory data structure stores hot pages (entities that are frequently accessed). A process called the buffer manager handles the data flow between the buffer cache and persistent storage (disk). In short this means:
- Handling modifications to pages that are currently kept in the buffer cache.
- Evicting the least recently used pages when new data needs to be loaded.
- Flushing dirty pages to the disk (persisting the committed data).
It is essential to keep frequently accessed data in memory and allow disk writes to occur less frequently, and the buffer cache is how PostgreSQL achieves this efficiency. This however, creates problem: What happens when uncommitted data is lost?
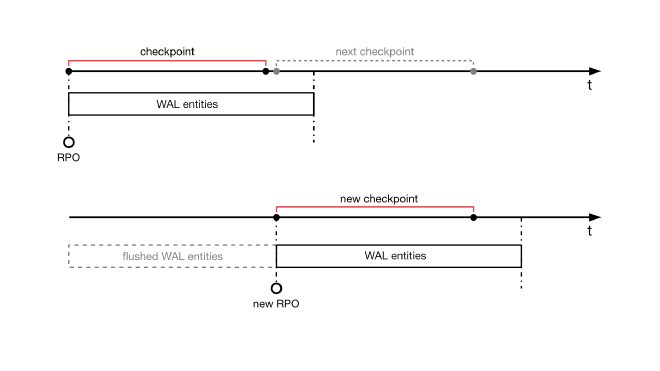
To achieve fault tolerance and durability, PostgreSQL uses WAL (Write-Ahead Logging). These logs keep a sequential record of relevant changes, including page modifications, transaction commits, rollbacks, and schema changes like table additions and removals.
A checkpoint mechanism compares Log Sequence Number (LSN) of the last page stored on the disk to the last WAL entry. This process establishes a recovery point of the system. As data changes are flushed to disk during checkpoints, older, no longer needed WAL files can be safely recycled or removed.
A Simple Replication Scenario #
In modern high-traffic production applications, it’s common to have at least one read-replica alongside the primary node. To keep things simple, I will not be discussing different architectures like primary-primary, and we will be assuming that the cluster is using physical replication.
PostgreSQL instances can be configured to serve as Hot Standby, which means a secondary server that is configured to serve read-only queries and is also ready to serve as the primary in case the initial primary becomes unavailable via failover.
Let’s look at the above concepts in a primary-secondary architecture where the cluster is configured to replicate data between the two instances.
Firstly, the same WAL records are sent to the replica server. PostgreSQL uses both streaming and archiving approaches to send WAL files to secondary nodes.
Archiving involves the primary sending filled and closed WAL files to a designated server for point-in-time recovery and redundancy.
Streaming provides a continuous stream of WAL records to achieve low-latency, real-time replication. This is typically used by clusters configured for high-availability, which is also the focus of this article.
Regardless of the transfer method, the replica uses the WAL records it receives to persist the changes to its own disk.
synchronous_commit #
The first configuration decision to be made is regarding synchronous_commit. This is a user-level parameter that is enabled by default to achieve strong ACID compliance. Disabling it (even partially) can bring performance gains without sacrificing “too much” on this department.
This parameter changes the WAL write mode. With asynchronous mode (synchronous_commit = off), WAL records are sent to the replica without the primary waiting for their confirmation. This gives replica more time to work with, but the application should be able to afford a form of data loss (no strong ACID compliance).
Synchronous commit has multiple modes, but we will discuss two relevant to replication: remote_write and remote_apply.
remote_apply is the mode that provides the strongest durability guarantee. In this mode, the primary will wait for WAL records to be both written and applied to the data files on the synchronous replica before confirming the transaction’s commit. This guarantees no data loss and immediate failover readiness for that committed transaction, but at the cost of additional latency on the primary.
remote_write is an interesting intermediate. In this mode, the primary waits until WAL records have been transferred to the synchronous replica and written to its operating system’s file system cache before confirming the transaction. This guarantees no data loss in the event of a PostgreSQL server crash on the primary (as the data is guaranteed to be on the replica’s OS cache), but there’s still a small window for data loss if the replica itself crashes before applying the changes to its data files.
In short, we could use this simplified equation for replication lag (relevant to asynchronous setups):
$Replication Lag = Twalgeneration + Ttransferwal + Tapplywal$
And claim that we are trading T applywal with acceptance of some form of data loss in an event of node failure/OS crash.
Other Replication Considerations #
Turning hot_standby_feedback on allows the replica to inform the primary about ongoing queries. This prevents the primary from prematurely vacuuming/removing old row versions that those ongoing replica queries might still need. This is almost always useful, as it avoids “canceling statement due to hot standby conflict” errors on the replica, as long as very long-running queries aren’t heavily used on the replica, which could otherwise cause excessive table bloat on the primary.
To avoid large amounts of WAL data and ensure better checkpointing behaviour, try to break down large and complex write queries into smaller chunks.
Using the right type of lock (or no lock if possible) sparingly would help prevent the replica from waiting for replaying changes made on the primary, as locks on the primary can sometimes manifest as contention during replay.
max_standby_streaming_delay #
When a long query is running on the replica and the relevant data on the primary is modified, WAL replay on the replica will be paused if that query needs the original version of the modified data. This behaviour is controlled by max_standby_streaming_delay.
When set to -1, the replay will wait indefinitely until the conflicting read query on the replica is completed. Setting a positive value (in milliseconds) will allow the long-running query to run until this threshold is reached. If the query exceeds this, it will be canceled with the following error:
'ERROR: canceling statement due to conflict with recovery'
Setting a value requires a good understanding of your application’s needs. While setting blanket values is possible, it’s not ideal. You should be able to estimate how long your typical read queries could take under load. Regardless of your decision, there are tradeoffs…
Setting a value that is too low could help keep replication lag down, but timing out your read queries could cause frequent retries. If the application isn’t configured to handle this properly, this could overload your read replica.
Setting a value that allows the replica to wait for too long (hence delaying the streaming) means higher replication lag. In a failover scenario, the replica might not be as immediately up-to-date. This can still be a good strategy if you are unsure exactly how long your queries could take and your application can tolerate higher replication lag.
An alternative approach would be to use a mechanism like pg_cron and selectively kill long-running queries on the replica. This gives you flexibility to pick and choose which queries are allowed to run for extended periods. This could be used together with a relatively high max_standby_streaming_delay value, providing a safety net.